Synthetic Data in Model Training in 2026
Synthetic Data in Model Training in 2026.
Synthetic Data has emerged as the "infinite fuel" for the Artificial Intelligence revolution of 2026. As the industry hit the "data wall" in 2024—the point where Large Language Models (LLMs) had essentially consumed the entire publicly available, high-quality human-generated internet—the shift toward machine-generated training data became a matter of survival.
In 2026, synthetic data is no longer a "poor substitute" for real-world data; in many cases, it is superior. It is cleaner, more diverse, and ethically compliant, allowing AI models to reach levels of reasoning and specialization that were previously impossible.
1. Why Synthetic Data? The End of the Human Data Era
For years, AI was trained on "scraped" data. This brought two massive problems: exhaustion and poisoning. By late 2025, there was simply no more high-quality human text left to scrape. Furthermore, because AI-generated content began to flood the internet, training a new model on the "public web" meant training it on the output of older, dumber AI—a phenomenon known as "Model Collapse."
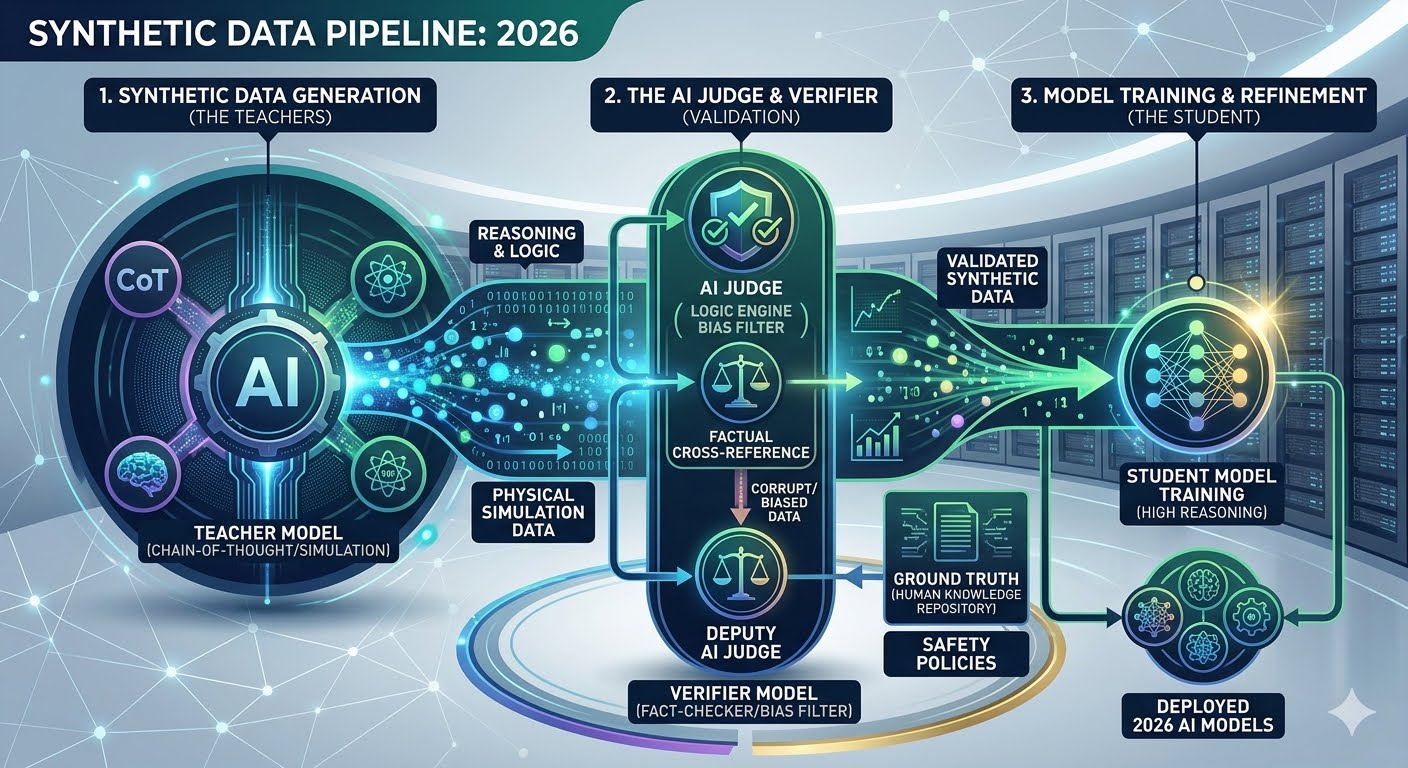
Synthetic Data solves this by using a "Teacher-Student" framework. Highly capable "Teacher" models (or specialized physics/logic engines) generate high-reasoning, error-free data specifically designed to teach "Student" models. This creates a virtuous cycle where models get smarter by learning from the best possible examples, rather than the "noisy" and often incorrect data found on social media or forums.
2. The Mechanics of 2026 Synthetic Data Generation
In 2026, synthetic data generation has evolved into three distinct categories:
A. Reasoning and Logic Synthesis
To improve AI's math and coding abilities, engineers don't just give the AI "answers." They use Chain-of-Thought (CoT) synthesis. The "Teacher" model generates millions of math problems and then writes out the step-by-step logical reasoning for each. This forces the "Student" model to learn the process of thinking, not just the final result.
B. Digital Twins and Physical Simulation
For robotics and autonomous vehicles, 2026 is the year of the "Omniverse." Instead of driving millions of miles on real roads, AI drivers are trained in hyper-realistic digital twins of cities. These simulations can generate "corner cases"—like a child chasing a ball into a fog-covered street at night—that are too dangerous or rare to capture in real life but are essential for safety.
C. Privacy-Preserving Tabular Data
In healthcare and finance, "real" data is locked behind privacy laws (GDPR, HIPAA). In 2026, organizations use Generative Adversarial Networks (GANs) to create synthetic versions of patient records. These records share the same statistical patterns as real patients (e.g., "People with Condition X usually respond to Medication Y") but do not correspond to any real individual, allowing for groundbreaking medical research without privacy risks.
3. The Quality Control Era: "Curation is the New Code"
The biggest challenge of 2026 isn't generating data; it's validating it. If an AI learns from "bad" synthetic data, it hallucinations become hardcoded. This has given rise to the Verifier Model.
Before synthetic data is fed to a training cluster, it passes through an "AI Judge." This judge uses formal logic and cross-referencing to ensure the data is:
Factually Accurate: Does this align with known laws of physics or math?
Diverse: Does this data represent a new concept, or is it just repeating what the model already knows?
Non-Toxic: Does it avoid the biases and harmful patterns found in human data?
In 2026, the most valuable "engineers" aren't those who write code, but "Data Architects" who design the recipes for these synthetic datasets.
4. Solving the "Bias" Problem
One of the most profound impacts of synthetic data in 2026 is its ability to re-balance the world. Human-generated data is inherently biased toward the languages and cultures that dominate the internet.
Synthetic data allows engineers to intentionally "over-sample" underrepresented languages, medical conditions, or cultural perspectives. If a model is weak in Swahili or struggles to identify rare skin diseases in darker skin tones, engineers simply "dial up" the synthesis of high-quality data in those specific areas. This makes AI in 2026 significantly more equitable than the models of the early 2020s.
5. The Economic Impact: The Data Sovereignty Shift
Synthetic data has disrupted the "Data Broker" industry. Companies that used to sell access to user data are finding their business models obsolete.
"In 2026, the competitive advantage isn't who has the most data, but who has the best generator."
Startups can now compete with tech giants because they no longer need 10 years of proprietary user data to build a smart model. They just need a clever synthetic data strategy and enough compute power to run the synthesis.
6. The Risks: The "Hallucination Loop"
Despite the progress, 2026 faces a new threat: Systemic Hallucination. If a major Teacher model has a subtle flaw in its logic, and it generates 80% of the data for the next generation of models, that flaw becomes "universal truth" for the AI. This is why "Ground Truth" (verified real-world data) remains the "gold standard" anchor that all synthetic pipelines must occasionally touch to stay calibrated.
7. Conclusion
Synthetic data in 2026 has transformed AI training from a "mining" operation into a "manufacturing" operation. We are no longer limited by what humans have happened to write down or record in the past. We can now create the specific knowledge we need to solve the problems of the future.
As we move toward Artificial General Intelligence (AGI), synthetic data will be the bridge that allows models to move beyond human-level performance and begin discovering scientific and mathematical truths that no human has ever conceptualized.
Did you find this ICT insight helpful?