Chi-Square Calculations in PSPP: A Step-by-Step Guide
Master Chi-Square Calculations in PSPP: A Step-by-Step Guide with Practical Examples.
In statistical analysis, understanding relationships between categorical variables is a fundamental requirement across disciplines—ranging from public health and marketing research to social sciences and quality control. While commercial software packages like IBM SPSS are widely used for this purpose, their steep licensing costs often present a barrier to students, independent researchers, and non-profit organizations.
Fortunately, PSPP offers a powerful, completely free, and open-source alternative. Designed as a drop-in replacement for SPSS, PSPP replicates its user interface, command syntax, and data handling logic.
This comprehensive guide will walk you through the theory and practical execution of Chi-Square (\(\chi ^{2}\)) tests using PSPP. We will explore both the Goodness-of-Fit Test and the Test of Independence using clear, step-by-step examples.
1. Understanding the Core Concepts of Chi-Square Tests
Before opening PSPP, it is critical to understand what a Chi-Square test does and when it should be applied. Chi-Square tests are non-parametric statistics, meaning they do not assume your data follows a normal distribution curve. Instead, they operate purely on frequencies (counts) within nominal or ordinal categorical data.
There are two primary flavors of the Chi-Square test, each answering a distinct research question:
A. The Chi-Square Goodness-of-Fit Test
This test evaluates a single categorical variable. It determines whether the observed distribution of data points across various categories matches an expected distribution (such as an equal split or a distribution derived from historical census data).
Research Question Example: Does a retail store attract an equal number of customers on every day of the week?
B. The Chi-Square Test of Independence (Crosstabulation)
This test evaluates two categorical variables simultaneously. It determines whether there is a statistically significant association between them, essentially checking if the distribution of one variable depends on the categories of the second variable.
Research Question Example: Is there a relationship between a person’s employment status (Employed vs. Unemployed) and their preferred mode of public transit (Bus, Train, or Taxi)?
Crucial Assumptions for All Chi-Square Tests
To ensure your PSPP output is valid, your dataset must meet these core assumptions:
Categorical Data: Variables must be nominal (e.g., gender, region) or ordinal (e.g., satisfaction level: low, medium, high).
Independence of Observations: Each subject or data point must occupy exactly one cell. You cannot have the same person counted multiple times across different categories.
Adequate Sample Size: A classic rule of thumb is that the expected frequency in any given cell should be 5 or greater for at least 80% of the cells. If your expected counts are too low, the test loses statistical power and accuracy.
2. Preparing and Structuring Data in PSPP
To follow along with our upcoming examples, you must understand how data can be entered into PSPP. PSPP allows for two distinct entry formats: Raw Individual Data and Weighted Aggregated Data.
Approach A: Entering Raw Individual Data
In this format, each row in your PSPP Data View represents a single, unique participant or observation. If you surveyed 150 people, your spreadsheet will have exactly 150 rows.
Example Columns:
Participant_ID,Gender,Job_Satisfaction.
Approach B: Entering Weighted Aggregated Data (Time-Saver)
If you already possess a summarized tally table (e.g., from a report), you do not need to manually type 150 rows. Instead, you create a summary grid with a dedicated Weight Variable.
Example Columns:
Gender,Job_Satisfaction, andCount.
How to Activate Weighting in PSPP:
If using Approach B, you must explicitly tell PSPP to treat your count column as a multiplier.
Navigate to the top menu and select Data \(\rightarrow \) Weight Cases...
In the dialog box that appears, select the radio button for Weight cases by.
Move your summary frequency variable (e.g.,
Count) into the Frequency Variable slot.Click OK. A small indicator reading "Weight On" will appear in the bottom-right status bar of your PSPP window.
3. Example 1: Chi-Square Goodness-of-Fit Test
Scenario
A university student council claims that student enrollment across four major academic tracks—Science, Arts, Business, and Engineering—is perfectly balanced, with an equal 25% distribution in each stream. A researcher collects a random sample of 200 students to test this hypothesis.
Hypothesis Formulation
Null Hypothesis (\(H_{0}\)): Student enrollment is uniformly distributed across all four academic tracks (Observed Frequencies = Expected Frequencies).
Alternative Hypothesis (\(H_{1}\)): Student enrollment is not uniformly distributed across the tracks; a preference pattern exists.
Step-by-Step Execution in PSPP
Step 1: Variable and Data Entry
Open PSPP and switch to the Variable View tab at the bottom left. Define your variable:
Name:
TrackType: Numeric
Label: Academic Track
Value Labels: Click the cell to define your categories:
1= Science2= Arts3= Business4= Engineering
Switch to the Data View tab. We will use the weighted frequency method for swift input. Create a second variable named Frequency, turn on Weight Cases, and enter the following counts:
Science (
1): 65 studentsArts (
2): 35 studentsBusiness (
3): 40 studentsEngineering (
4): 60 students
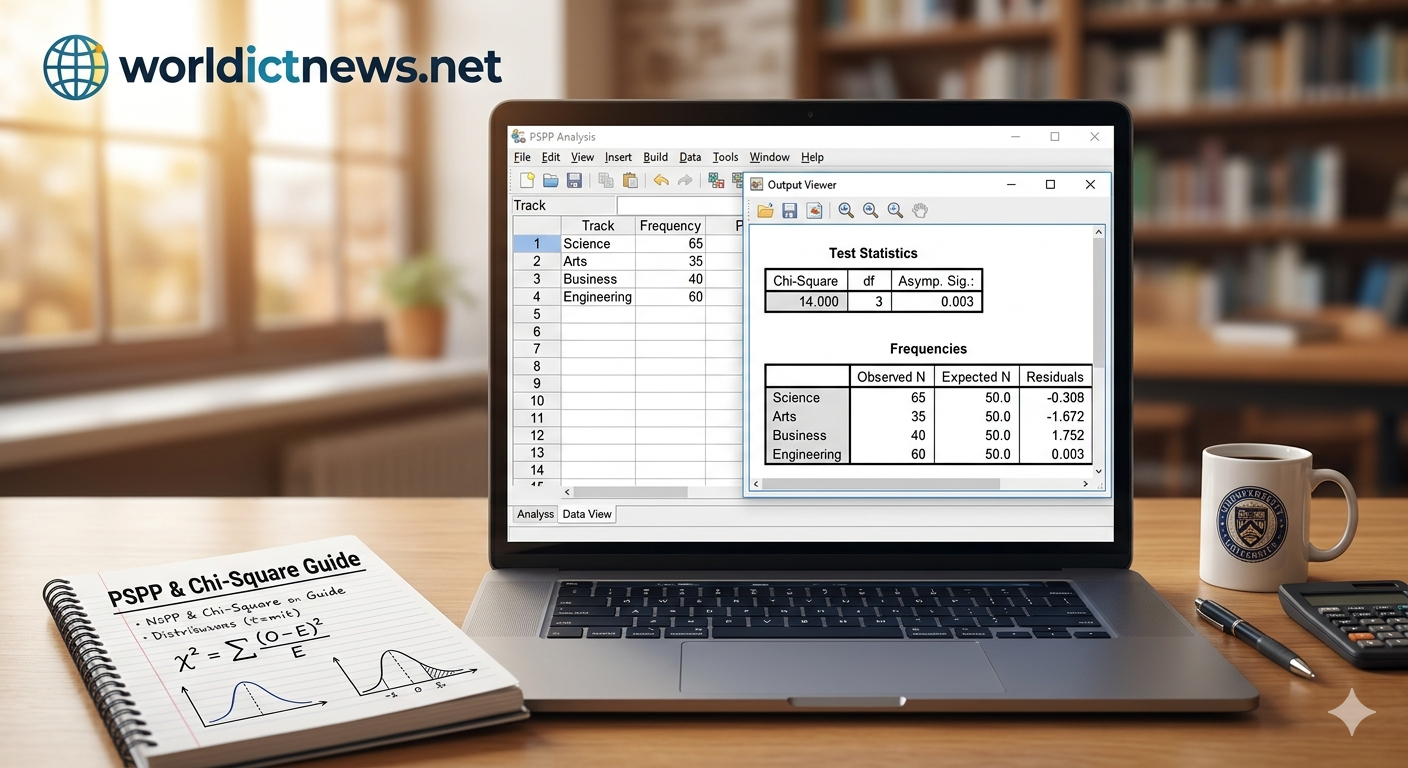
[Data View Layout]
Track | Frequency
---------------------
1.00 | 65.00
2.00 | 35.00
3.00 | 40.00
4.00 | 60.00
Step 2: Running the Analysis
Go to the top navigation bar and select: Analyze \(\rightarrow \) Non-Parametric Tests \(\rightarrow \) Chi-Square...
A dialog box will open. Select your variable
Academic Track [Track]from the left panel and click the arrow button to move it into the Test Variable List.Under the Expected Values section, leave the default option selected: All categories equal (since our null hypothesis tests an equal 25% split).
Click OK.
+-------+
| Chi-Square Test |
+--------+
| Test Variable List: Expected Values: |
| +-------+ (x) All categories equal|
| | [Track] | ( ) Values: [ ] |
| +-------+ |
+----------+
Interpreting the Output Window
PSPP will launch its Output Viewer window containing two primary tables:
Table 1: Frequencies
This table displays your category names alongside three crucial metrics: Observed N (your actual data: 65, 35, 40, 60), Expected N (calculated by dividing the total sample of 200 by 4 categories, yielding 50 per cell), and the Residual (Observed minus Expected).
Table 2: Test Statistics
This contains the mathematical conclusion of your test:
Chi-Square Value: \(\chi^2 = 14.00\)
Degrees of Freedom (df): Calculated as \(k - 1\) (where \(k\) is the number of categories). \(4 - 1 = 3\).
Asymp. Sig. (p-value): This is the most critical number for decision-making. Let us assume it reads
0.003.
+-----------------------------------+
| Test Statistics |
+-----------------------------------+
| Chi-Square | 14.000 |
| df | 3 |
| Asymp. Sig. | 0.003 |
+-----------------------------------+
Statistical Conclusion
Because our asymptotic significance value (\(p = 0.003\)) is substantially lower than our standard alpha threshold of \(0.05\), we reject the null hypothesis (\(H_{0}\)).
Reporting the result: "A Chi-Square Goodness-of-Fit test indicated that student enrollment was not equally distributed across academic tracks, \(\chi^2(3) = 14.00, p < 0.01\)." The data shows that Science and Engineering tracks have higher enrollment numbers than expected, while Arts and Business lag behind.
4. Example 2: Chi-Square Test of Independence (Two Variables)
Scenario
A public health organization wants to know whether there is an association between an individual's Physical Activity Level (Sedentary vs. Active) and their self-reported Sleep Quality (Poor, Average, Good). They survey a sample of 300 adults.
Hypothesis Formulation
Null Hypothesis (\(H_{0}\)): Physical activity level and sleep quality are independent of one another (no relationship exists).
Alternative Hypothesis (\(H_{1}\)): Physical activity level and sleep quality are dependent/associated with one another.
Step-by-Step Execution in PSPP
Step 1: Define Variables
Open a new dataset tab in PSPP and navigate to Variable View. Configure three distinct variables:
Name:
ActivityLabel: Physical Activity Level
Value Labels:
1= Sedentary,2= Active
Name:
SleepLabel: Sleep Quality
Value Labels:
1= Poor,2= Average,3= Good
Name:
CountLabel: Number of Respondents (Remember to apply Data \(\rightarrow \) Weight Cases using this variable!)
Step 2: Populate the Data Matrix
Switch over to Data View. Because we have 2 activity levels multiplied by 3 sleep tiers, we must enter all 6 unique combinations along with their aggregated counts:
Activity | Sleep | Count
------------------------------
1 (Seden) | 1 (Poor) | 55.00
1 (Seden) | 2 (Aver) | 60.00
1 (Seden) | 3 (Good) | 35.00
2 (Active) | 1 (Poor) | 25.00
2 (Active) | 2 (Aver) | 65.00
2 (Active) | 3 (Good) | 60.00
Step 3: Executing the Crosstabs Procedure
Navigate to the top menu option: Analyze \(\rightarrow \) Descriptive Statistics \(\rightarrow \) Crosstabs...
A configuration panel will populate.
Select
Physical Activity Level [Activity]from your variable repository and transfer it to the Row(s) box using the corresponding arrow button.Select
Sleep Quality [Sleep]and transfer it into the Column(s) box.Click the Statistics... button located at the bottom of the dialog window. Check the box labeled Chi-square, then click Continue.
(Optional but highly recommended) Click the Cells... button. Under Counts, make sure Observed and Expected are both selected. This step helps you easily verify the "minimum cell count of 5" assumption. Click Continue.
Click OK to process.
+-------+
| Crosstabs |
+------+
| Variables: Row(s): |
| +-----+ +------+ |
| | | --> | [Activity] | |
| +-----+ +----+ |
| Column(s): |
| +-----+ |
| | [Sleep] | |
| +-----+ |
| [Statistics...] (Chi-Square checked) |
+--------+
Interpreting the Output Window
Your PSPP Output Viewer will generate three core panels:
1. Case Processing Summary
This simple tracking card displays the sample breakdown. It confirms that 100% of your 300 targeted analytical cases were safely captured without encountering missing cell exclusions.
2. Activity * Sleep Crosstabulation
Because we enabled Expected Counts, each intersection square will contain two data values:
Observed Count: The real-world data points we manually entered.
Expected Count: What the software calculates assuming no relationship exists between exercise and sleep. For instance, notice that for the Sedentary \(\times \) Poor Sleep intersection, the observed count (55) is noticeably higher than the mathematically expected baseline pattern (40.0).
3. Chi-Square Tests Table
Look closely at the row header designated as Pearson Chi-Square:
+-------+
| Chi-Square Tests |
+--------+
| | Value | df | Asymp. Sig. (2- |
| | | | sided) |
+----+---+---+----+
| Pearson Chi-Square | 17.216 | 2 | 0.000 |
| N of Valid Cases | 300 | | |
+--------+
Value: The calculated test statistic (\(\chi^2 = 17.216\)).
df (Degrees of Freedom): Calculated using the formula \((R - 1) \times (C - 1)\), where \(R\) equals rows and \(C\) equals columns. For our layout: \((2 - 1) \times (3 - 1) = 1 \times 2 = 2\).
Asymp. Sig. (2-sided): The calculated probability value (\(p = 0.000\)). Note that in statistical output,
0.000does not mean zero probability; it means the p-value is extremely small (\(p < 0.001\)).
Statistical Conclusion
Because our calculated asymptotic significance value (\(p < 0.001\)) falls comfortably below the critical \(0.05\) threshold, we reject the null hypothesis (\(H_{0}\)).
Reporting the result: "A Pearson Chi-Square Test of Independence demonstrated a statistically significant association between an individual's physical activity level and their reported sleep quality, \(\chi^2(2) = 17.22, p < 0.001\)."
By cross-referencing our observed versus expected cell counts, we can infer that sedentary individuals experience a disproportionately higher rate of poor sleep quality, whereas active individuals achieve average or good sleep marks at rates higher than expected.
5. Troubleshooting Common Errors in PSPP
When conducting Chi-Square procedures inside PSPP, you may occasionally encounter error notifications or confusing outputs. Use this quick reference guide to resolve common issues:
Issue A: The output table displays fractional frequencies (e.g., 23.40 rows)
The Cause: You forgot to turn off the Weight Cases tool from a previous analytical run, or you selected an incorrect weighting variable column.
The Fix: Go to Data \(\rightarrow \) Weight Cases, choose the radio button for Do not weight cases, and click OK to reset your configuration baseline.
Issue B: The Asymptotic Significance value reads completely blank or returns .
The Cause: This occurs if your dataset lacks data variation, such as entering data where all respondents select a single option. This results in a matrix with 0 degrees of freedom, making division operations mathematically impossible.
The Fix: Double-check your data layout in Data View. Ensure you have entered your value categories and counts correctly across distinct categorical rows.
Issue C: A warning note states "Expected values are less than 5"
The Cause: Your overall sample size is too small, or your data points are distributed across too many complex categorical choices. This directly violates our minimum cell size assumption.
The Fix: You must collect a larger data sample, or combine related low-frequency categories to simplify your matrix. For example, you could merge an "Extremely Dissatisfied" choice category into a broader "Dissatisfied" group using the Transform \(\rightarrow \) Recode into Different Variables utility.
Did you find this ICT insight helpful?