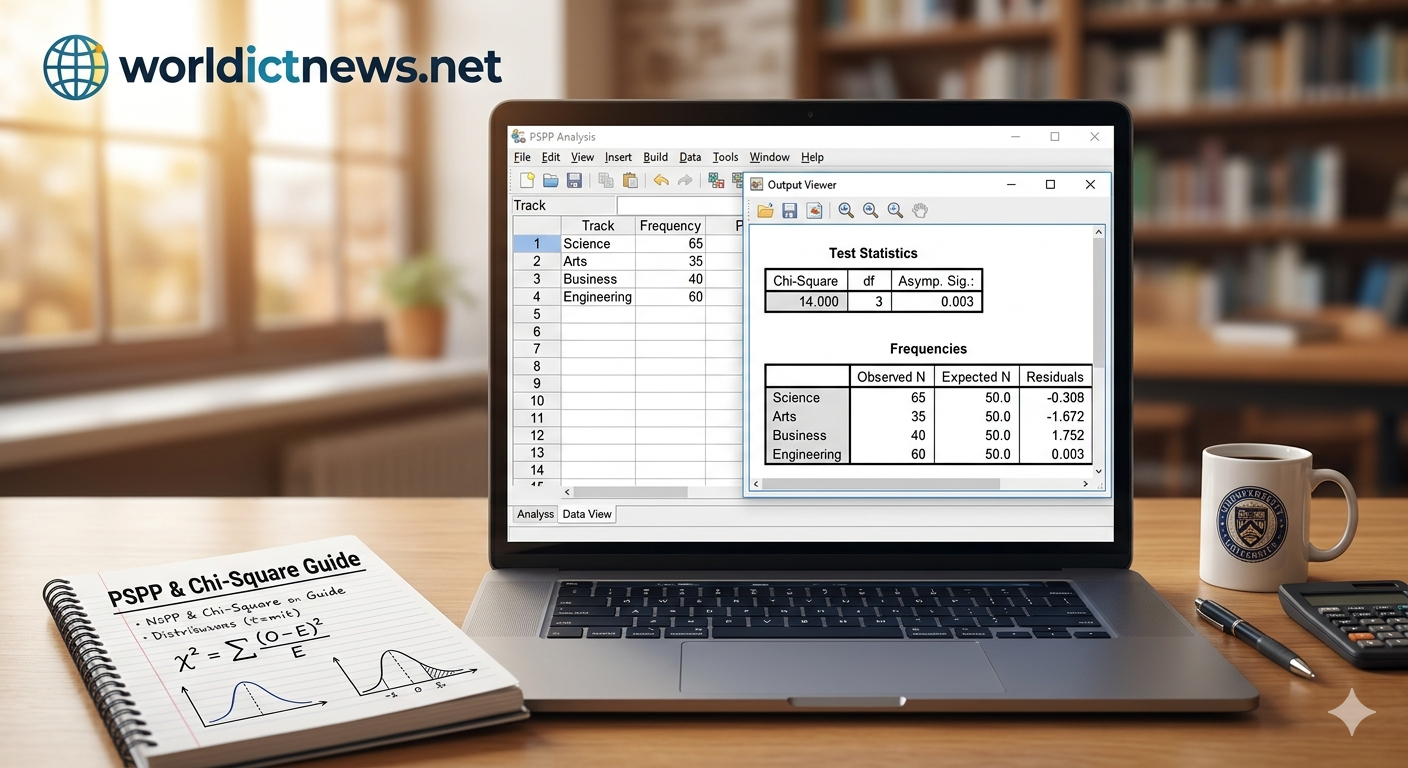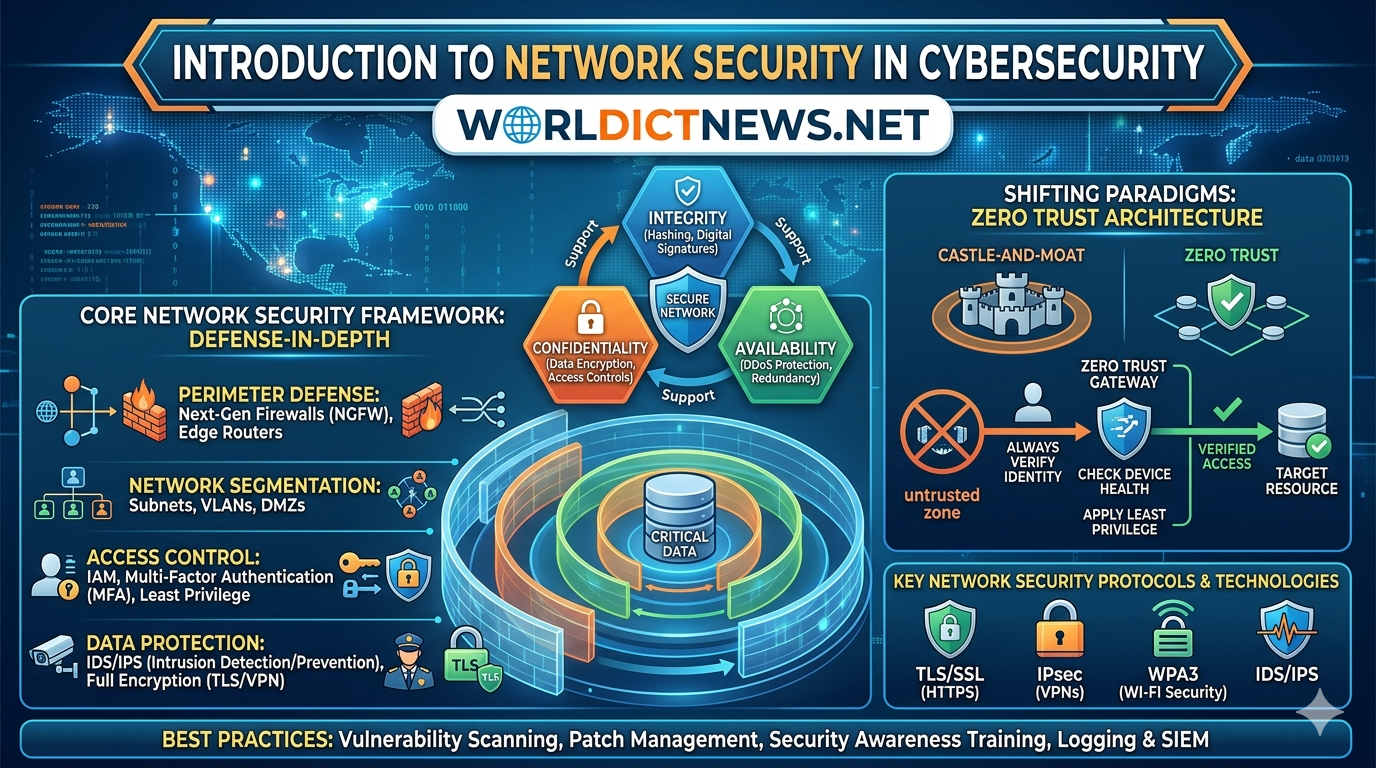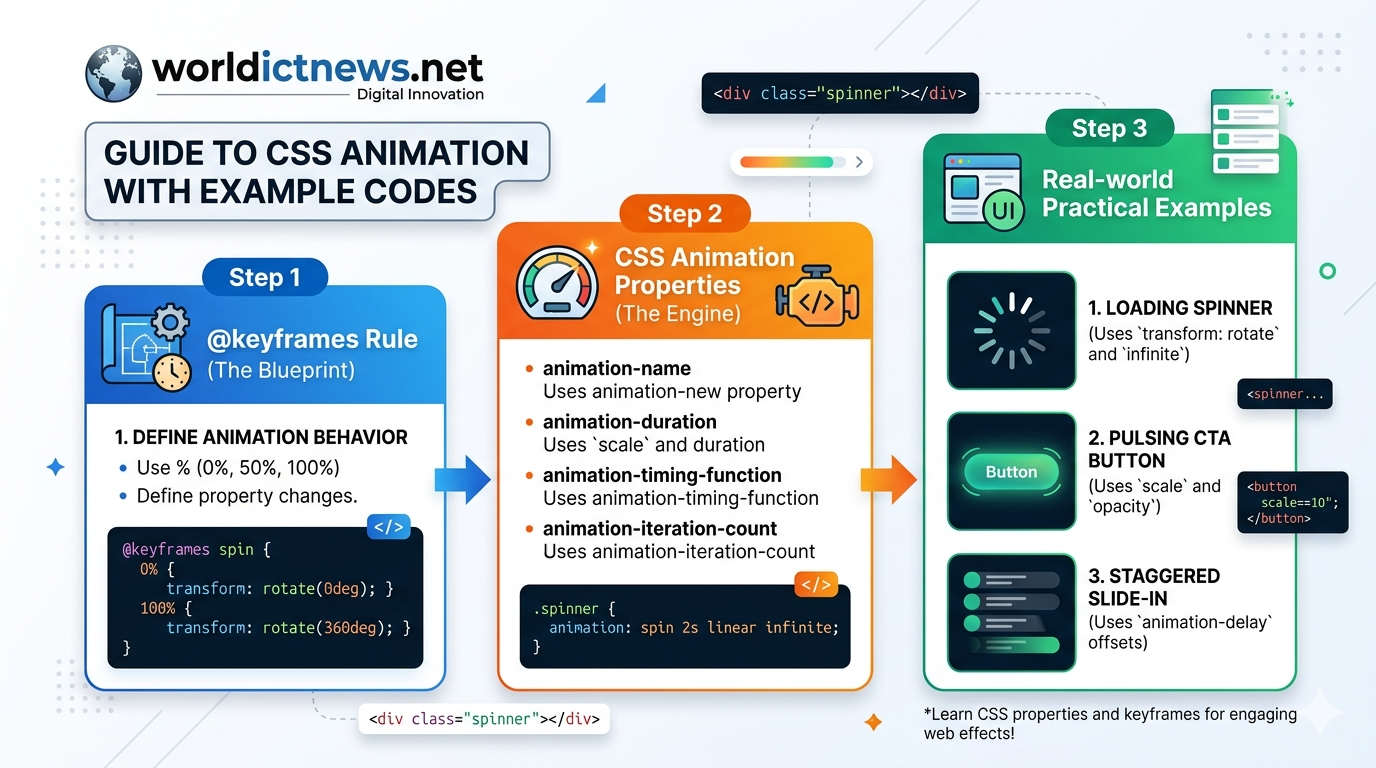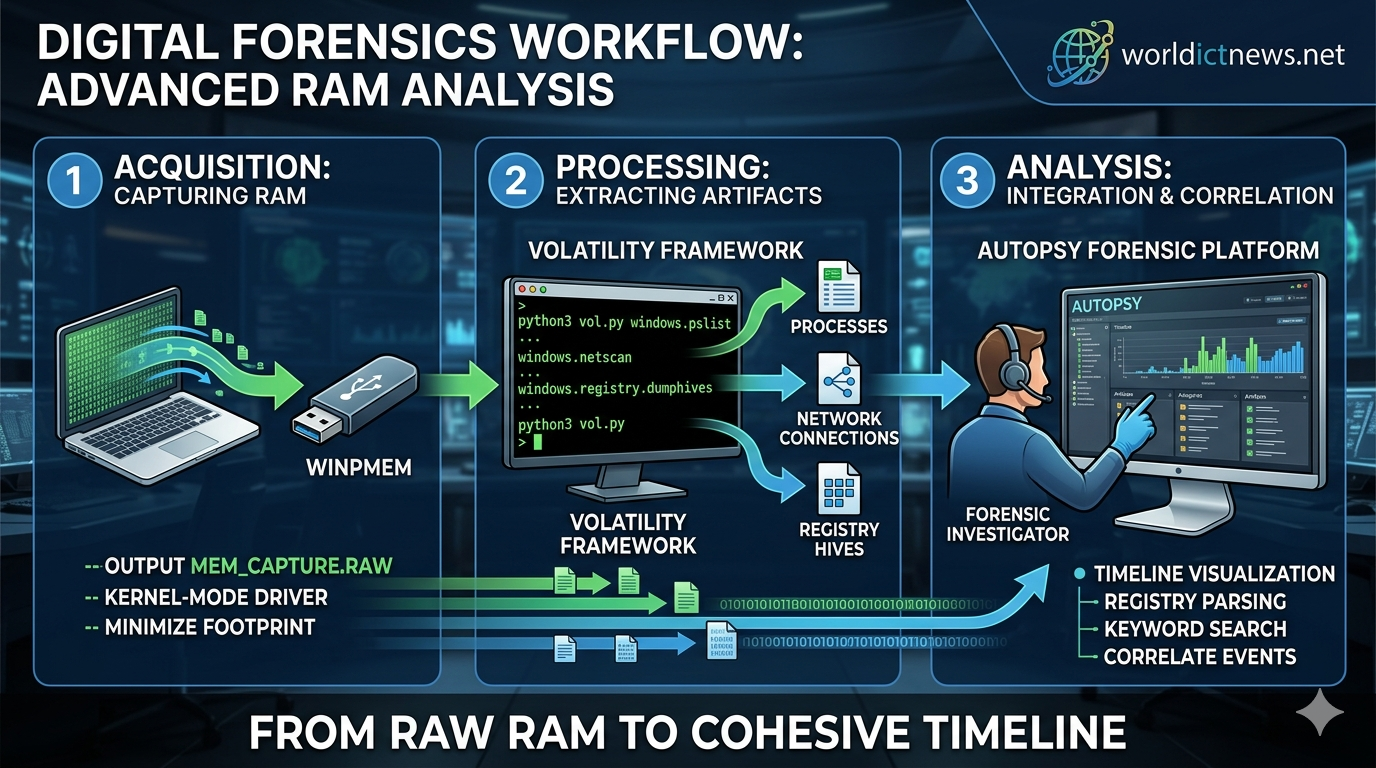
Jun 09, 2026
8 min read
Responsive Interfaces: An Introduction to the Bootstrap CSS Framework
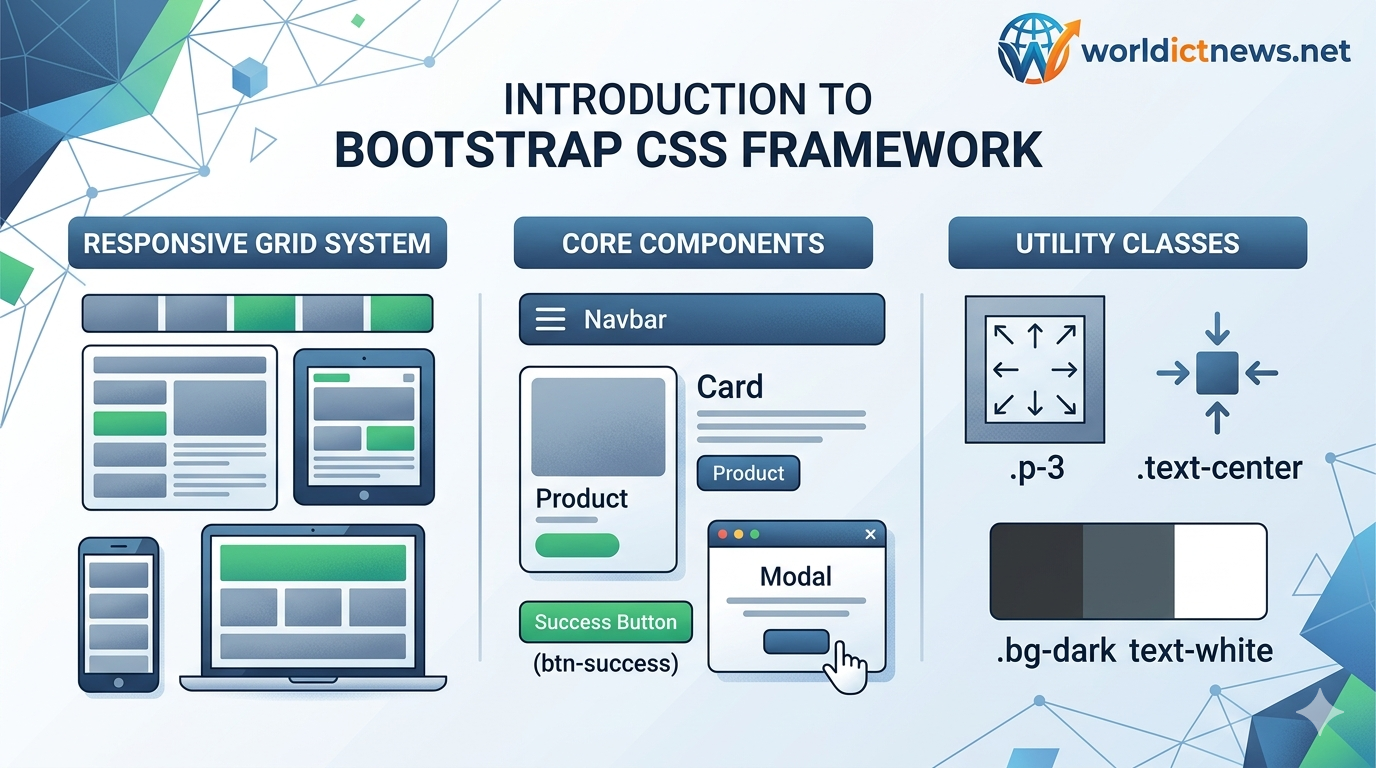
Crafting Responsive Interfaces: An Introduction to the Bootstrap CSS Framework. In the early days of web development, building a website that looked good on both a desktop monitor and a mobile phone required writing massive, complex style sheets from scratch. Developers spent countless hours wrestling with CSS floats, media queries, and browser compatibility bugs just to align a basic navigation bar or button grid.This landscape shifted dramatically in August 2011 when Mark Otto and Jacob Thornton, two developers at Twitter, released Bootstrap as an open-source project. Originally designed as an internal tool to ensure design consistency across Twitter’s corporate applications, Bootstrap quickly grew into the most popular front-end framework in the world.Today, Bootstrap serves as the foundation for millions of websites. This introduction will explore what Bootstrap is, look at its core architecture, examine its powerful grid system, and show you how to build modern web interfaces using this open-source tool.1. What is Bootstrap?At its core, Bootstrap is a free, open-source front-end framework consisting of pre-compiled CSS and JavaScript templates. It provides web developers with an extensive kit of ready-to-use user interface (UI) components—such as buttons, forms, navigation bars, cards, modal windows, and carousels.+-------------------------------------------------------------+| BOOTSTRAP ENGINE |+-------------------------------------------------------------+ | | | v v v[ Responsive Grid ] [ Pre-built UI Components ] [ Utility Classes ]- Flexbox-based - Navbar, Cards, Buttons - Spacing (m-3, p-2)- 12-column layout - Modals & Dropdowns - Typography & ColorsInstead of writing custom CSS rules to style a webpage from scratch, developers simply download Bootstrap and apply pre-defined class names to standard HTML elements.Why Use a CSS Framework?Rapid Development Speed: Instead of designing a polished button or navigation bar layout from the ground up, you can build a complete, production-ready prototype in minutes using Bootstrap's components.Responsive Design by Default: Every element within Bootstrap is built with mobile responsiveness in mind. Your website automatically scales down for smartphones, layout structures shift for tablets, and columns expand gracefully on high-resolution monitors.Cross-Browser Consistency: Different web browsers (Chrome, Safari, Firefox, Edge) occasionally render raw CSS properties differently. Bootstrap includes a CSS normalization baseline called Reboot that smooths over these browser inconsistencies, ensuring your application looks uniform everywhere.Massive Community Ecosystem: Because Bootstrap is so widely adopted, finding templates, tutorials, and third-party plugins is effortless.2. Core Architecture and Mobile-First PhilosophyUnderstanding Bootstrap requires embracing a mobile-first design philosophy. In older web design models, developers built a comprehensive desktop site first, then used media queries to hide or compress elements for smaller screens.Bootstrap flips this approach upside down. Its styles are written for the smallest screens first (smartphones), and then progressively enhanced for larger screen viewports using minimum-width (min-width) media queries. This logic optimizes mobile performance by preventing smaller devices from processing bulky desktop-centric styles.The Breakpoints BlueprintBootstrap segments different device screen widths into logical brackets called breakpoints. These breakpoints correspond to standard device viewports and are controlled by shorthand class modifiers:BreakpointClass AbbreviationDimensionsTarget DeviceExtra SmallNone< 576pxPortrait SmartphonesSmallsm≥ 576pxLandscape SmartphonesMediummd≥ 768pxTabletsLargelg≥ 992pxLaptops / Smaller MonitorsExtra Largexl≥ 1200pxDesktop MonitorsExtra Extra Largexxl≥ 1400pxUltra-wide Displays3. The Heart of Bootstrap: The 12-Column Grid SystemThe single most powerful feature of Bootstrap is its responsive grid system. Built on top of CSS Flexbox layout logic, the grid uses a series of containers, rows, and columns to align content.The system divides the horizontal width of a webpage into 12 equal, invisible columns. Developers choose how many of these columns a specific element should occupy.+-----------------------------------------------------------------------+| .container || +-----------------------------------------------------------------+ || | .row | || | +---------------+ +---------------+ +---------------+ | || | | .col-md-4 | | .col-md-4 | | .col-md-4 | | || | | (Takes 4 cols)| | (Takes 4 cols)| | (Takes 4 cols)| | || | +---------------+ +---------------+ +---------------+ | || +-----------------------------------------------------------------+ |+-----------------------------------------------------------------------+The Grid Components1. Containers (.container or .container-fluid)Containers are the outer structural walls of your layout. A regular .container centers your content on the page and applies fixed widths based on the active breakpoint. A .container-fluid spans the full width of the screen, edge to edge.2. Rows (.row)Rows act as horizontal wrappers that sit inside containers. Rows ensure that your individual columns stack neatly next to each other.3. Columns (.col-*)Columns are where your actual text, images, and components live. Columns must always be direct children of a .row.A Practical Grid Layout ExampleConsider a scenario where you want to display three feature boxes side-by-side on a desktop computer, but you want them to stack on top of each other when viewed on a phone. The HTML code looks like this:html<div class="container"> <div class="row"> <div class="col-12 col-md-4"> <h3>Feature A</h3> <p>This is the first feature box description.</p> </div> <div class="col-12 col-md-4"> <h3>Feature B</h3> <p>This is the second feature box description.</p> </div> <div class="col-12 col-md-4"> <h3>Feature C</h3> <p>This is the third feature box description.</p> </div> </div></div>Use code with caution.Deconstructing the Codecol-12: By default, on mobile screens (extra-small viewports), each box will take up all 12 available columns, forcing them to stack vertically.col-md-4: When the viewport expands to a medium screen size (tablets and laptops, ≥ 768px), the layout switches engine rules. Each box now takes up exactly 4 columns. Because 4 + 4 + 4 = 12, all three feature boxes align side-by-side across a single row.4. Exploring Essential ComponentsBootstrap includes dozens of pre-designed interface modules. By leaning on these components, you don't have to spend hours writing custom styles for common web UI features.Navigation Bars (.navbar)The navigation bar is a staple of modern web design. Bootstrap's navbar component includes automated mobile collapse logic out of the box. On desktop viewports, it displays a standard horizontal navigation bar with links and dropdowns. On a smartphone screen, it automatically collapses behind a standard "hamburger" icon menu, expanding smoothly when tapped.Cards (.card)Cards serve as clean, flexible data containers. They group related information together by combining headers, text, contextual buttons, and cover images inside a cleanly bordered box. Cards are widely used to display blog article loops, e-commerce product grids, or profile dashboards.html<div class="card" style="width: 18rem;"> <img src="product.jpg" class="card-img-top" alt="Product Image"> <div class="card-body"> <h5 class="card-title">E-Commerce Product</h5> <p class="card-text">A high-quality product description paragraph goes here.</p> <a href="#" class="btn btn-primary">Buy Now</a> </div></div>Use code with caution.Utility ClassesIn addition to large components, Bootstrap provides thousands of tiny, single-purpose helper styles called Utility Classes. These let you adjust padding, margins, colors, and borders instantly without writing a single line of custom CSS.m-3 / p-2: Applies an all-around margin level of 3 or padding level of 2.text-center: Automatically shifts your text alignment to the center.bg-dark text-white: Inverts an element into a dark-themed container with white text.5. Integrating Bootstrap into a ProjectThere are two primary ways to add Bootstrap to a web development project.Approach 1: Using a Content Delivery Network (CDN) - Quickest MethodIf you are building a simple website or a quick prototype, you can link to Bootstrap’s files directly from a public server by adding two lines of code to your HTML file:html<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Bootstrap Quickstart</title> <!-- Bootstrap Compiled CSS Link --> <link href="https://jsdelivr.net" rel="stylesheet"></head><body> <div class="container mt-5"> <h1 class="text-primary">Hello, Bootstrap!</h1> <button class="btn btn-success">Success Button</button> </div> <!-- Bootstrap JS Bundle Link (Includes Popper.js for dropdowns/modals) --> <script src="https://jsdelivr.net"></script></body></html>Use code with caution.Approach 2: Using a Package Manager (NPM) - Professional MethodFor large, enterprise-level web applications, developers install Bootstrap directly into their project environment via terminal package managers:bashnpm install bootstrap
Use code with caution.This local installation allows developers to open Bootstrap’s source Sass files, modify global theme colors (such as changing the default blue brand color to a custom corporate green), and strip out unused modules to make production bundle file sizes as light as possible.6. ConclusionBootstrap revolutionized front-end web development by proving that responsive, consistent UI design doesn't require reinventing the wheel for every new project. By offering a robust 12-column flexbox grid, an extensive library of accessible UI components, and intuitive utility helper classes, it empowers developers to build production-ready applications with remarkable speed.While modern CSS advancements like native Grid and Flexbox give developers more layout control than ever before, Bootstrap remains a valuable asset for quick prototyping, building internal corporate tools, and providing an organized design system for large dev teams.