May 26, 2026
7 min read
A Step-by-Step Technical Guide to Penetration Testing Procedures
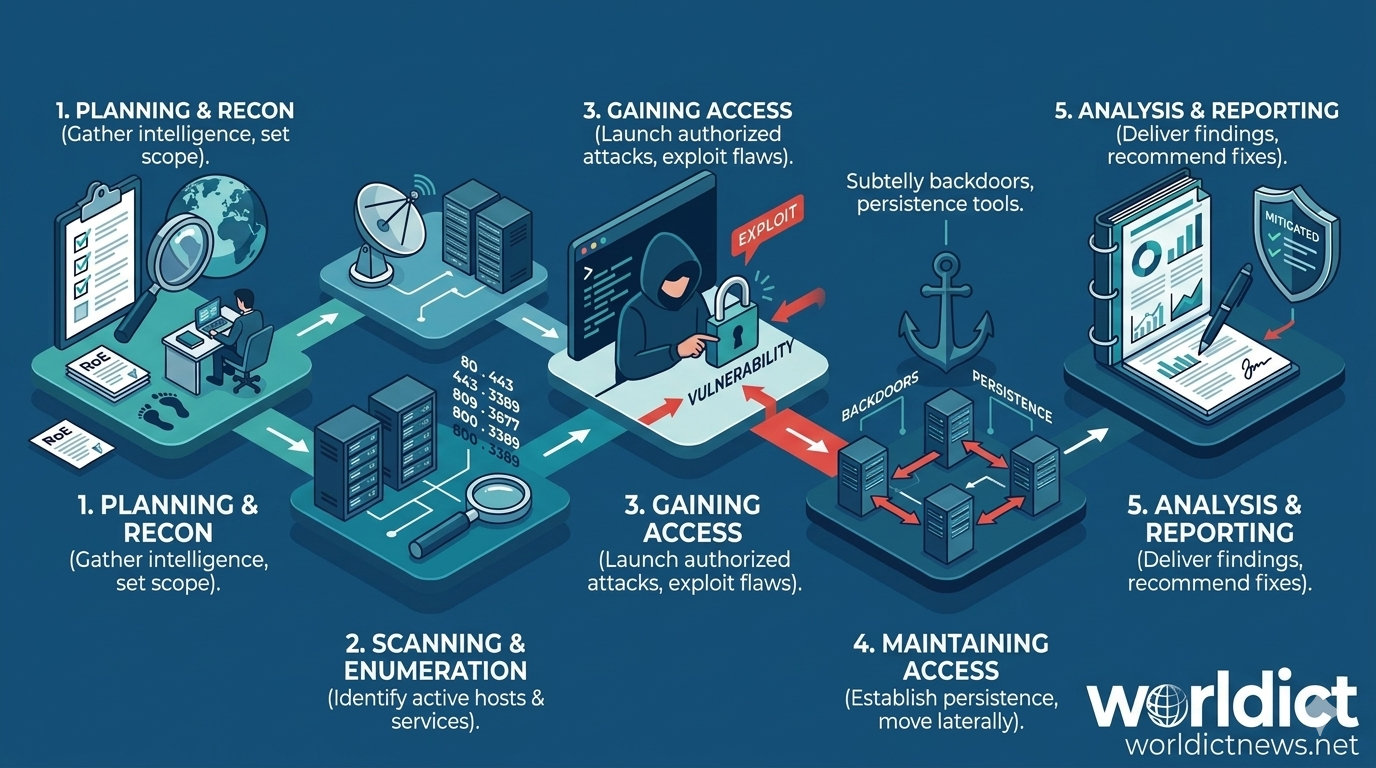
Behind the Shield: A Step-by-Step Technical Guide to Penetration Testing Procedures. In an era where data breaches cost organizations millions of dollars per incident, waiting for a cyberattack to happen is no longer an option. Reactive security is broken. To truly defend an infrastructure, security teams must adopt the mindset of an adversary.This proactive philosophy is realized through penetration testing (or pen testing)—the authorized, simulated attack against an organization's IT systems to uncover exploitable vulnerabilities.Conducting a successful penetration testing engagement requires strict adherence to a structured, repeatable methodology. Without a rigorous procedure, testing becomes chaotic, critical vulnerabilities are missed, and the risk of accidentally disrupting production systems increases.Here is the comprehensive, step-by-step procedure utilized by elite cybersecurity professionals to execute an end-to-end penetration test.🧭 The Five Core Phases of a Penetration TestA professional penetration test relies on five distinct, sequential phases. Each phase acts as a foundation for the next, moving systematically from initial administrative planning to final remediation tracking.┌────────┐│ Phase 1: Planning and Reconnaissance │└────────┘ │ ▼┌────────┐│ Phase 2: Scanning & Enumeration │└────────┘ │ ▼┌────────┐│ Phase 3: Gaining Access │└────────┘ │ ▼┌────────┐│ Phase 4: Maintaining Access & Pivoting │└────────┘ │ ▼┌────────┐│ Phase 5: Analysis and Reporting │└────────┘🛠️ Phase 1: Planning, Scoping, and ReconnaissanceThe first phase is part administrative and part technical. Before a single packet is sent over the network, the parameters of the engagement must be explicitly defined.1. Legal and Operational ScopingA penetration test without clear authorization is a cybercrime. This step establishes the legal boundaries of the engagement.Rules of Engagement (RoE): A document detailing exactly when the testing can occur, what tools are forbidden, and who to contact in case of an emergency or unexpected system outage.Scope Definition: Explicitly lists allowed targets (IP addresses, specific web applications, physical locations) and explicitly excluded assets (critical legacy servers, third-party cloud integrations).Sign-off: Executing signatures on a mutual Non-Disclosure Agreement (NDA) and a "Permission to Attack" form.2. Reconnaissance (Information Gathering)Once authorized, the pen tester gathers intelligence on the target ecosystem using open-source intelligence (OSINT) and passive discovery techniques. The goal is to map out the target's digital footprint without directly alerting their defensive monitoring tools.Passive Reconnaissance: Gathering publicly available data. This includes researching employee names and email patterns on LinkedIn, analyzing DNS records, searching public source code repositories (like GitHub) for leaked API keys, and scouring the dark web for compromised employee credentials.Active Reconnaissance: Interacting slightly closer with the targets, such as inspecting public SSL/TLS certificates and running basic domain queries to understand the underlying infrastructure hosting the company's assets.🔍 Phase 2: Scanning and EnumerationWith a map of the target's assets in hand, the tester moves to active network discovery. This phase aims to discover live hosts, open network ports, and running software services.1. Port ScanningUsing tools like Nmap or Masscan, the tester probes the target systems to find open access points. They look for exposed services such as web servers (ports 80/443), database servers (ports 1433/3306), or remote access points (ports 22/3389).2. Service and Operating System DetectionFinding an open port is not enough; the tester must identify the exact version of the software running on that port. If an Apache web server is identified as version 2.4.49, the tester immediately notes that this specific version is vulnerable to known path traversal exploits.3. Vulnerability AssessmentThe tester runs automated vulnerability scanners (such as Nessus, OpenVAS, or Qualys) against the discovered services. These tools cross-reference the active software versions against public databases of known vulnerabilities (Common Vulnerabilities and Exposures, or CVEs).Crucial Distinction: A vulnerability assessment merely points out potential holes; the penetration test must proceed to the next phase to confirm if those holes can actually be breached.🔓 Phase 3: Gaining Access (Exploitation)This is the phase where the simulated attack occurs. Armed with the list of vulnerabilities discovered in Phase 2, the penetration tester attempts to bypass security controls to gain an initial foothold inside the network.1. Flaw ExploitationTesters map specific CVEs to weaponized code samples, often utilizing framework toolsets like Metasploit, or tailoring custom exploit scripts. If a server has an unpatched remote code execution vulnerability, the tester executes the exploit code to force the system to yield command-line access.2. Web Application AttacksIf the target is a web application, testers look for flaws defined by the OWASP Top 10 framework, including:SQL Injection (SQLi): Injecting malicious database queries into input fields to bypass authentication or steal data.Cross-Site Scripting (XSS): Injecting malicious scripts into a trusted website to run inside a victim’s browser.Broken Access Control: Manipulating parameters or URLs to access data belonging to other users.3. Social EngineeringHuman error is often the easiest vulnerability to exploit. Testers may deploy controlled phishing emails mimicking internal IT services to harvest corporate login credentials from employees.⚓ Phase 4: Maintaining Access and Post-ExploitationGaining an initial foothold is only half the battle. In a real-world scenario, attackers want to stay inside a network long enough to locate high-value data assets.[ Initial Foothold ] ──► [ Privilege Escalation ] ──► [ Lateral Movement/Pivoting ]1. Establishing PersistenceIf the compromised system restarts, the tester’s access could be lost. To prevent this, they install subtle backdoors, create stealthy service accounts, or configure scheduled cron jobs that regularly dial back to the tester’s command-and-control (C2) server.2. Privilege EscalationInitial access often yields low-privileged user accounts with restricted system access. Post-exploitation requires finding local misconfigurations, weak file permissions, or unpatched kernel flaws to elevate access from a standard user to a local Administrator or Root user.3. Lateral Movement and PivotingOnce the tester controls a machine inside the internal network, they use that machine as a launching pad to attack other internal systems that were previously shielded from the outside internet. This process, known as pivoting, allows the tester to move systematically through the network until they reach critical assets like Domain Controllers or financial databases.4. Data Collection (Exfiltration Demonstration)To prove the business risk to stakeholders, testers locate sensitive assets (e.g., proprietary designs, customer credit card records, employee data) and safely stage mock data to demonstrate how an attacker could extract it from the company network.📊 Phase 5: Analysis, Reporting, and RemediationA penetration test is only as good as the actionable intelligence it delivers back to the organization. The final phase shifts focus entirely onto documentation and risk reduction.1. Technical CleanupBefore leaving the network, testers must meticulously remove all traces of the simulated attack. This includes deleting uploaded web shells, removing created user accounts, stopping active backdoor processes, and ensuring all targeted systems are left in a stable condition.2. Drafting the Comprehensive ReportThe penetration testing report serves as a formal documentation package for two entirely different audiences:Executive Summary: A high-level overview written in clear, non-technical language designed for C-level executives (CEO, CFO, CISO). It outlines the overall security posture, maps findings to business risk, and estimates potential financial exposure.Technical Findings & Detailed Breakdowns: A granular technical breakdown created for the engineering and sysadmin teams.ComponentTechnical Detail RequiredVulnerability ClassificationStandardized CVSS (Common Vulnerability Scoring System) risk ratings.Proof of Concept (PoC)Step-by-step reproduction instructions and screenshots showing exactly how the flaw was exploited.Remediation PlanActionable advice, including code patches, configuration changes, or software updates to mitigate the risk.3. Remediation and Re-testingAfter the technical team implements the suggested patches, the penetration testing cycle concludes with a focused validation test. The testers attempt to exploit the exact same vulnerabilities a second time to ensure the fixes are robust and correctly implemented.🏁 ConclusionPenetration testing is not a one-time checklist item; it is an iterative, evolving security process. As new code is deployed and network architectures shift, new security gaps will inevitably emerge. By embedding this structured, step-by-step methodology into regular corporate evaluation cycles, organizations can successfully identify and neutralize network vulnerabilities long before malicious actors have the chance to find them.